ChatGPT has revolutionized how we interact with artificial intelligence, transforming natural language processing from a specialized field into an accessible tool used by millions worldwide. Understanding how this remarkable system works provides insights into one of the most significant technological breakthroughs of our time.
What is ChatGPT?
ChatGPT (Chat Generative Pre-trained Transformer) is a large language model developed by OpenAI, designed to generate human-like text based on the input it receives. Built on the Generative Pre-trained Transformer (GPT) architecture, specifically GPT-3.5 and GPT-4, ChatGPT represents the culmination of decades of research in natural language processing and machine learning.
The Foundation: Transformer Architecture
Understanding Transformers
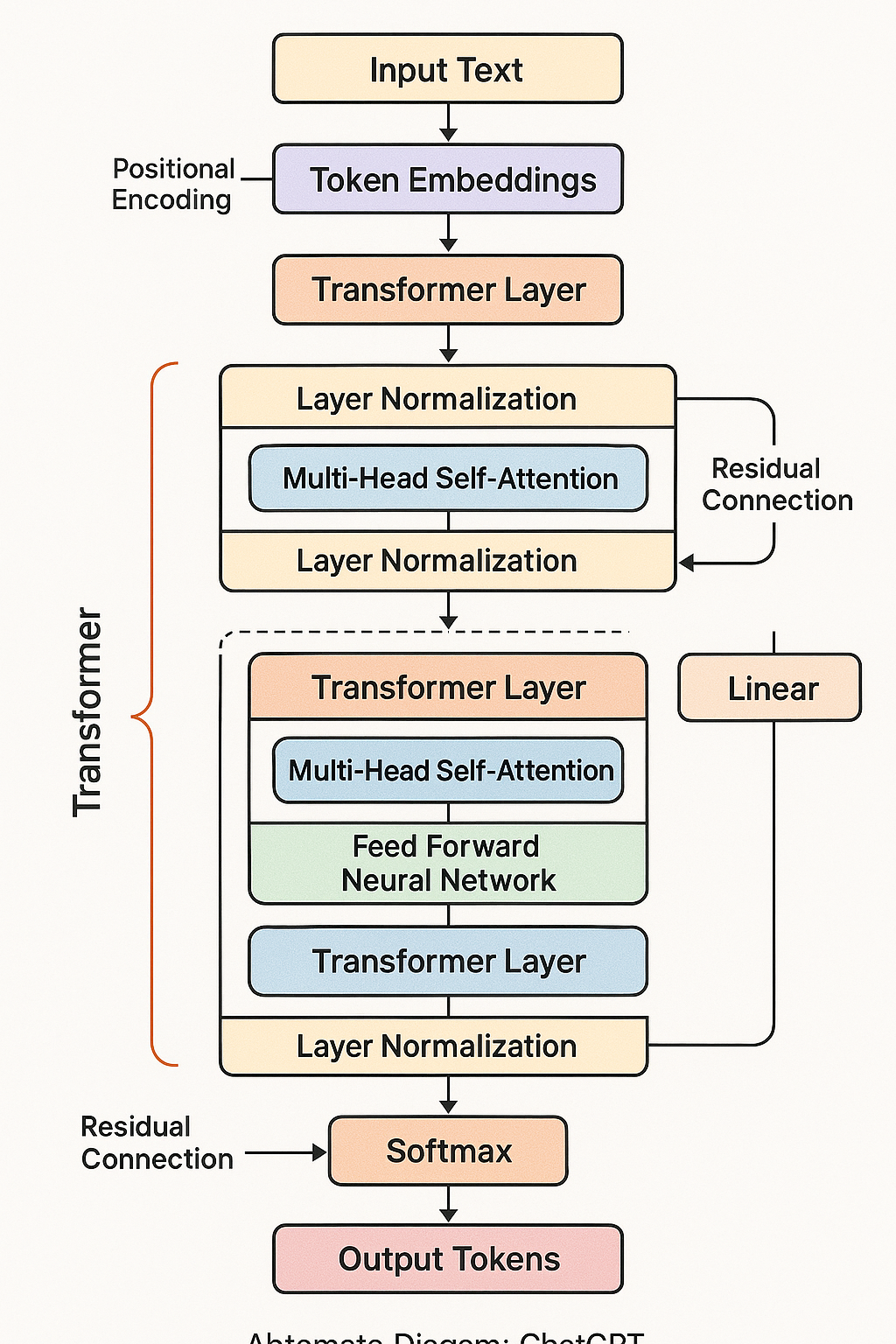
At its core, ChatGPT is built on the transformer architecture, a revolutionary neural network design introduced in 2017. Unlike previous sequential models that processed text word by word, transformers can analyze entire sequences simultaneously, making them incredibly efficient and powerful for language tasks.
Key Components of the Transformer
1. Multi-Head Self-Attention Mechanism
The attention mechanism is ChatGPT's most crucial component, allowing the model to focus on different parts of the input text simultaneously. This mechanism works through three key matrices:- Query Matrix: Represents what the model is looking for
- Key Matrix: Represents what information is available
- Value Matrix: Contains the actual information to be processed
The self-attention mechanism enables each word to "attend" to every other word in the sequence, helping the model understand context and relationships throughout the entire text.
2. Feed-Forward Neural Networks
After the attention mechanism processes the input, feed-forward networks apply non-linear transformations to further refine the representation. These networks help the model learn complex patterns and relationships in the data.3. Positional Encoding
Since transformers don't process data sequentially like traditional recurrent neural networks, they need a way to understand word order. Positional encoding adds information about each token's position in the sequence, helping ChatGPT maintain coherent understanding of sentence structure.The Training Process: From Raw Text to Conversational AI
Phase 1: Pre-training
Massive Data Ingestion: ChatGPT was initially trained on enormous amounts of text data from the internet, including books, articles, websites, and other written content. This training corpus contains billions of words representing diverse topics, writing styles, and domains of knowledge. Next-Word Prediction: During pre-training, the model learns to predict the next word in a sequence given all previous words. This seemingly simple task requires understanding grammar, context, facts about the world, and reasoning patterns. Pattern Recognition: Through this process, ChatGPT develops an internal representation of language, learning statistical patterns, semantic relationships, and contextual dependencies.Phase 2: Fine-tuning with Human Feedback
Supervised Fine-tuning: After pre-training, the model undergoes fine-tuning on a more specific dataset with human trainers providing conversations and model-generated responses. This step helps align the model with desired conversational behavior. Reinforcement Learning from Human Feedback (RLHF): ChatGPT's development incorporates a sophisticated training technique where human evaluators rank different model responses. The model learns to optimize for responses that humans prefer, improving its helpfulness, harmlessness, and honesty.How ChatGPT Processes and Generates Text
Input Processing Pipeline
1. Tokenization
When you input text, ChatGPT breaks it down into smaller units called tokens. These tokens can be words, parts of words, or even individual characters, depending on the language and context.2. Embedding Creation
Each token is converted into a dense vector representation (embedding) that captures semantic meaning. These embeddings allow the model to work with numerical representations of language.3. Context Building
The model combines token embeddings with positional encodings to create a comprehensive representation of the input that preserves both meaning and structure.The Generation Process
1. Attention Computation
ChatGPT uses its multi-head attention mechanism to analyze relationships between all tokens in the input, building a rich understanding of context and meaning.2. Probability Distribution
After processing through multiple transformer layers, the model generates a probability distribution over its entire vocabulary for the next token. This distribution represents how likely each possible word is to come next.3. Token Selection
ChatGPT selects the next token based on the probability distribution, using techniques like temperature sampling to balance between predictability and creativity.4. Iterative Generation
This process repeats iteratively, with each newly generated token becoming part of the context for generating the next token, building complete responses word by word.Technical Specifications and Scale
Model Architecture Details
Parameter Count: GPT-3.5 contains 175 billion parameters, while GPT-4 is estimated to have over 1 trillion parameters. These parameters represent the model's learned knowledge and capabilities. Layer Structure: ChatGPT consists of multiple stacked transformer layers, each containing attention mechanisms and feed-forward networks. GPT-3.5 has 96 layers, while GPT-4 has even more. Context Window: The model can process contexts of thousands of tokens simultaneously, allowing it to maintain coherent conversations and work with lengthy documents.Training Infrastructure
Computational Requirements: Training ChatGPT required massive computational resources, including thousands of high-end GPUs running for months. Data Processing: The training process involved processing petabytes of text data, requiring sophisticated data filtering and preprocessing techniques.Advanced Capabilities and Features
Contextual Understanding
ChatGPT excels at maintaining context throughout conversations, remembering earlier parts of discussions and providing coherent, relevant responses. This capability emerges from its attention mechanism and large parameter count.
Multi-turn Conversations
The model can engage in extended dialogues, adapting its responses based on the conversation history and maintaining consistent personality and knowledge throughout interactions.
Task Versatility
ChatGPT demonstrates remarkable versatility, capable of:
- Creative Writing: Generating stories, poems, and scripts
- Code Generation: Writing and debugging software in multiple programming languages
- Analysis and Reasoning: Breaking down complex problems and providing structured solutions
- Translation: Converting text between different languages
- Summarization: Condensing long documents into key points
Limitations and Challenges
Knowledge Cutoffs
ChatGPT's training data has a specific cutoff date, meaning it lacks knowledge of events occurring after training. This limitation affects its ability to discuss recent developments or provide up-to-date information.
Hallucinations
The model can sometimes generate confident-sounding but factually incorrect information, a phenomenon known as "hallucination". This occurs because ChatGPT is trained to produce plausible-sounding text rather than verified facts.
Bias and Fairness
Like all AI models trained on internet data, ChatGPT can exhibit biases present in its training data. OpenAI has implemented various measures to mitigate these issues, but challenges remain.
Reasoning Limitations
While ChatGPT demonstrates impressive reasoning capabilities, it can struggle with complex logical puzzles, mathematical calculations, and tasks requiring precise factual accuracy.
The Role of Reinforcement Learning
Human Preference Learning
RLHF allows ChatGPT to learn human preferences without explicit programming. Human trainers rank different model outputs, and the system learns to produce responses that align with human values and expectations.
Reward Modeling
The training process includes developing reward models that predict human preferences, allowing the system to optimize responses even when human feedback isn't directly available.
Continuous Improvement
This approach enables ongoing refinement of the model's behavior, making it more helpful, harmless, and honest over time.
Computational Requirements and Efficiency
Inference Optimization
Running ChatGPT requires significant computational resources. Each response generation involves processing through billions of parameters, requiring powerful GPU infrastructure.
Scaling Challenges
Serving millions of users simultaneously presents enormous technical challenges, requiring sophisticated load balancing, caching, and optimization techniques.
Energy Considerations
The computational intensity of large language models raises important questions about energy consumption and environmental impact.
Future Developments and Improvements
Multimodal Capabilities
Future versions of ChatGPT are expected to handle multiple input types, including text, images, audio, and video, creating more versatile AI assistants.
Improved Reasoning
Ongoing research focuses on enhancing logical reasoning, mathematical capabilities, and factual accuracy while maintaining conversational fluency.
Reduced Hallucinations
Developers are working on techniques to improve factual accuracy and reduce the generation of false or misleading information.
Efficiency Improvements
Research continues on making large language models more efficient, reducing computational requirements while maintaining or improving performance.
Practical Applications and Impact
Education and Learning
ChatGPT serves as a powerful educational tool, providing personalized tutoring, explaining complex concepts, and assisting with research and writing tasks.
Content Creation
The model assists writers, marketers, and creators in generating ideas, drafting content, and refining their work across various formats and styles.
Programming and Development
Developers use ChatGPT for code generation, debugging, documentation, and learning new programming languages and frameworks.
Business and Professional Use
Organizations leverage ChatGPT for customer service, content marketing, data analysis, and process automation.
Security and Safety Measures
Content Filtering
OpenAI has implemented various safety measures to prevent ChatGPT from generating harmful, inappropriate, or dangerous content.
Usage Monitoring
The system includes monitoring and rate limiting to prevent abuse and ensure responsible use.
Ethical Guidelines
Development follows strict ethical guidelines aimed at creating beneficial AI that serves humanity's best interests.
Conclusion
ChatGPT represents a remarkable achievement in artificial intelligence, combining sophisticated transformer architecture with innovative training techniques to create a conversational AI that can assist with an enormous range of tasks. Its ability to understand context, generate coherent text, and engage in natural conversations stems from its massive scale, careful training process, and the fundamental power of the transformer architecture.
Understanding how ChatGPT works helps us appreciate both its capabilities and limitations. While it represents a significant step forward in AI development, it's important to recognize that it remains a tool – albeit a powerful one – that augments rather than replaces human intelligence and creativity.
As this technology continues to evolve, we can expect even more sophisticated AI systems that better understand human needs, provide more accurate information, and assist us in solving increasingly complex challenges. The principles underlying ChatGPT's architecture will likely serve as the foundation for future AI breakthroughs that further transform how we interact with technology.
ChatGPT's success demonstrates the potential of large-scale AI systems to understand and generate human language, opening new possibilities for human-computer interaction and collaboration.